
Deep Spelling - Hệ thống Kiểm lỗi chính tả tiếng Việt
I. Giới thiệu về Sản phẩm và nhóm Tác giả
Hệ thống Deep Spelling được phát triển bởi nhóm tác giả là giảng viên và sinh viên Trường ĐH Tôn Đức Thắng, TP Hồ Chí Minh, bao gồm:
1.1. PGS.TS. Lê Anh Cường, Trưởng Phòng thí nghiệm Xử lý gôn ngữ tự nhiên và Khai phá tri thức, Khoa Công nghệ Thông tin, Trường ĐH Tôn Đức Thắng (TDTU)
1.2. Sinh viên Nguyễn Trọng Hiếu - TDTU, nghiên cứu tại Phòng thí nghiệm Xử lý gôn ngữ tự nhiên và Khai phá tri thức, Khoa Công nghệ Thông tin, Trường ĐH Tôn Đức Thắng
Sản phẩm được tài trợ bởi Công Ty Cổ Phần Ademax - Chi nhánh Hồ Chí Minh, 51 Trương Quốc Dung, Phường 10, Phú Nhuận, Thành phố Hồ Chí Minh.
Trang web sử dụng hệ thống: https://deepspell.net/spelling
Hệ thống đã được sử dụng trong thực tế trên Web và cho một số đơn vị.
II. Giới thiệu bài toán kiểm lỗi chính tả Tiếng Việt
2.1. Bài toán và Ý nghĩa
Lỗi chính tả xuất hiện trong các văn bản có thể ảnh hưởng tới chất lượng của văn bản, gây cảm xúc tiêu cực ở người đọc. Trong một số trường hợp, đối với văn bản hay bản tin của các cơ quan nhà nước, lỗi chính tả còn gây ra sự không chính xác về nội dung, ảnh hưởng tới uy tín của đơn vị phát hành văn bản, và cũng làm giảm tính nghiêm túc của thông tin mà văn bản muốn truyền tải.
Lỗi chính tả xảy ra có thể do lỗi đánh máy gây sai âm tiết, do nhầm lẫn phụ âm, nhầm dấu hỏi ngã, do dùng phương ngữ, do dùng từ sai (cụm từ hay dùng sai một cách phổ biến), hoặc một số trường hợp đặc biệt hơn như viết thừa từ, thiếu từ, sai quy tắc viết tên riêng, cách đánh dấu thanh. Chúng ta thường hoàn thành một văn bản bằng cách soạn thảo và sau đó rà soát lại vài lần để sửa nội dung và kiểm tra chính tả. Tuy nhiên một số lỗi chính tả vẫn có thể bị sót và một số trường hợp không phát hiện ra do bản thân người viết bị nhầm lẫn. Lỗi chính tả càng tăng lên đối với các văn bản dài và trong trường hợp cần hoàn thành gấp văn bản soạn thảo.
Vì vậy, việc xây dựng một hệ thống thông minh, tự động phát hiện lỗi chính tả là một nhiệm vụ quan trọng để hỗ trợ con người trong việc nâng cao chất lượng văn bản. Bài toán Kiểm lỗi chính tả Tiếng Việt đã được nghiên cứu từ lâu trong cộng đồng nghiên cứu về trí tuệ nhân tạo và xử lý ngôn ngữ tự nhiên. Một số hệ thống ứng dụng cũng đã được xây dựng và thử nghiệm thực tế, tuy nhiên chất lượng chưa thực sự tốt khi dùng trong thực tế và vì vậy chưa phổ biến. Vì vậy hiện tại đa số chúng ta vẫn đang sử dụng công cụ đơn giản có sẵn trong các hệ soạn thảo văn bản, như trong MS Word, để chủ yếu kiểm tra một từ có nằm trong từ điển không.
Gần đây, với sự phát triển đột phá của các công nghệ học máy (Machine Learning) và công nghệ xử lý ngôn ngữ tự nhiên (Natural Language Processing), các mô hình xử lý ngôn ngữ tự nhiên tự động đã trở nên khả thi hơn khi ứng dụng vào thực tế. Hệ thống phát hiện và sửa lỗi chính tả Deep Spelling ra đời nhờ ứng dụng công nghệ học máy tiên tiến nhất đồng thời với các cải tiến riêng mới cho ngôn ngữ Tiếng Việt. Hệ thống Deep Spelling là một công cụ hữu ích trong việc nâng cao chất lượng soạn thảo văn bản Tiếng Việt.
2.2. Các loại lỗi chính tả tiếng Việt
Các loại lỗi chính tả có thể được nhóm thành các loại như sau:
2.2.1. Lỗi sai âm tiết
Ví dụ: “Chính phủ họp tháo gowx khó khăn, vướng mắc chjo thị trường BĐS”
Lỗi này thường được phát hiện bằng cách kiểm tra xem âm tiết đó có thuộc từ điển âm tiết hay không. Tuy nhiên cách này thường nhận nhầm từ đúng thành lỗi đối với một số từ viết tắt, từ kí hiệu đặc biệt, tên riêng, hoặc từ nước ngoài.
2.2.2. Lỗi nhầm lẫn giữa các cặp phụ âm: tr/ch, s/x, d/gi/r, c/k/q, ng/ngh
Ví dụ: “Xác xuất có điều kiện và công thức Bayes”
(nguồn:https://maths.uel.edu.vn/Resources/Docs/SubDomain/maths/THONGKEBAYES/C1.pdf)
Các lỗi loại này gặp khá thường xuyên trong cả văn bản chính thống và cả các hội thoại thông thường. Loại lỗi này có thể dễ được nhận biết vì nó thường xuất hiện trong các từ ghép, tuy vậy vẫn có những trường hợp nhầm lẫn nếu không xét ngữ cảnh của từ.
Ví dụ: xét độc lập thì “trứng giám” là từ sai và sẽ được sửa thành “chứng giám”. Tuy nhiên trong câu sau thì không sai:
“Britain's Got Talent bị nghi dàn xếp vụ ném trứng giám khảo”
2.2.3. Lỗi nhầm lẫn dấu thanh, chủ yếu là cặp dấu hỏi – dấu ngã: ?/~
Có hiện tượng là nhiều người không phân biệt được khi nào thì dùng dấu hỏi, khi nào thì dùng dấu ngã. Hơn nữa, một số vùng miền trong phát âm đang bị lẫn lộn giữa hai âm này, hoặc chỉ thường dùng âm dấu ngã. Vì vậy lỗi này khá là phổ biến.
Ví dụ một số lỗi: “Nhiều người xem không nhịn được cười khi nhìn thấy hành động cực dễ thương của chú mèo sau khi ngả vào bát sửa”. ngả -> ngã; sửa -> sữa
“Nga sữa soạn tấn công miền đông để lập hành lang với Crimea.”: sữa -> sửa
“Những người đồng đội của anh thì thẩn thờ, thất vọng, nuối tiếc và có lẽ là chưa thể chấp nhận nổi thực tế quá phũ phàng.”: thẩn thờ -> thẫn thờ
Tuy nhiên trường hợp này lại rất cần ngữ cảnh, thậm chí phải ngữ cảnh rộng thì mới xét đúng được một từ là sai hay đúng.
2.2.4. Lỗi phương ngữ
Một số phương ngữ đã dẫn đến sử dụng nhầm đối với một số vần như: ươn/ương, an/ang, ân/âng, ước/ướt, …
Ví dụ: “Ban tổ chức xác định được tất cả 16 đội vược qua vòng bảng Cúp C1 châu Âu 2022/2023.”: vược -> vượt
“Từ xưa, ghế băng ngoài trời trên sâng trường thường là những hàng ghế đá.”: sâng trường -> sân trường
Lỗi kiểu này thường gặp trong học sinh, trong ngôn ngữ thường ngày, nhưng đối với các văn bản chính thống thì ít khi xảy ra. Tuy nhiên trong văn bản chính thống thì vẫn xảy ra hiện tượng này và xảy ra là do hiện tượng lỗi typing chứ không phải là nhầm lẫn về kiến thức.
Xác định được lỗi chính tả này phải dựa vào ngữ cảnh
2.2.5. Lỗi dùng từ sai
Một số lỗi chính tả hay dùng sai và khó phân biệt, số lượng dùng sai nhiều khi còn nhiều hơn số lượng dùng đúng. Ví dụ một số trường hợp:
Chín mùi - chín muồi => Từ đúng là chín muồi (chín, độ phát triển đầy đủ nhất)
Thăm quan - tham quan => Từ đúng là tham quan (ngắm cảnh, quan sát)
Tựu chung - tựu trung => Từ đúng là tựu trung (Tóm tắt lại, nói chung là...)
Chuẩn đoán - chẩn đoán => Từ đúng là chẩn đoán (Bác sỹ xác định đó là bệnh gì)
Đều như vắt chanh => vắt tranh => Đúng là: Đều như vắt tranh
2.2.6. Lỗi dấu cách
Lỗi vị trí thường xảy ra đối với việc sử dụng các dấu câu như , ; : ! ? viết đúng là các dấu phải sát vào từ phía trước. Đối với các kí hiệu mở như ( [ ‘ “ thì phải sát vào từ phía sau, và các kí hiệu đóng như ) ] ’ ” thì phải sát vào từ phía trước.
Ví dụ:
Câu viết sai: Sau một hồi suy nghĩ , cô gái nói với chàng trai : “ em không thích đi xem phim tối nay !”.
Viết đúng phải là: Sau một hồi suy nghĩ, cô gái nói với chàng trai: “em không thích đi xem phim tối nay!”.
2.2.7. Lỗi viết hoa tên riêng
Hiện tượng viết tên riêng một cách lộn xộn đang rất phổ biến. Nguyên nhân là do quy định mới (Nghị định số 30/2020/NĐ-CP của Chính phủ: Về công tác văn thư) khác với trước kia. Bên cạnh đó, sai còn là do viết một cách tuỳ ý theo chủ quan của người viết.
Ví dụ:
Cách viết sai: Trường đại học Công nghệ thuộc Đại học Quốc Gia Hà nội
Cách viết đúng: Trường Đại học Công nghệ thuộc Đại học Quốc gia Hà Nội
Nhận xét chung:
Bên cạnh các lỗi theo các hiện tượng như trên thì lỗi chính tả trong thực tế thường đa dạng hơn, có thể là kết hợp của nhiều kiểu lỗi trên. Trong nhiều trường hợp không thể xác định được lỗi nếu không xét ngữ cảnh (các từ xung quanh), hoặc thậm chí phải xét ngữ cảnh rộng (ví dụ ngữ nghĩa cả câu) thì mới có thể xác định được lỗi và gợi ý từ viết đúng.
Vì vậy mà bài toán xác định lỗi chính tả và gợi ý từ đúng là bài toán khó, và với các phương pháp truyền thống trước đây (sử dụng từ điển, sử dụng luật và các phương pháp học máy thông thường) sẽ khó mà xây dựng được một hệ thống chất lượng tốt đủ dùng trong thực tế.
III. Giải pháp Deep Spelling
3.1. Các tiếp cận chung
Đối với bài toán Spelling, có một số tiếp cận như sau:
3.1.1. Tiếp cận dựa trên từ điển
Đây là tiếp cận đơn giản và hiện tại đang được sử dụng trong một số bộ soạn thảo văn bản. Cách thức phát hiện lỗi trong tiếp cận này là với mỗi từ X cần kiểm tra, sẽ tìm kiếm trong từ điển xem X có tồn tại hay không.
Tiếp cận này thường sử dụng thêm độ đo khoảng cách giữa các từ (dùng Levenshtain distance) để phát hiện lỗi chính xác hơn.
3.1.2. Tiếp cận dựa trên luật (ràng buộc) và n-gram
Tiếp cận này bản chất là sử dụng thông tin thống kê tần suất các cụm từ để phát hiện lỗi và sửa lỗi. Thông tin thống kê sẽ giúp sử dụng được ngữ cảnh trong quá trình phát hiện lỗi và sửa lỗi.
Điểm chính yếu của phương pháp là sử dụng các ràng buộc về từ điển, về từ ghép, dùng Levenshtain distance, sử dụng các quy tắc sai chính tả, sử dụng thông tin thống kê trên cụm n-gram để đưa ra quyết định.

H1. Mô hình Spelling dựa trên thống kê và luật.
Nhược điểm của phương pháp này là nó phải sử dụng các ngưỡng (được xác định một cách heuristic) để đưa ra quyết định. Phương pháp này sẽ gặp nhiều trường hợp bị bắt lỗi sai và bắt sót lỗi.
3.1.3. Tiếp cận dựa trên học máy
Tiếp cận dựa trên học máy sẽ mô hình hoá bài toán kiểm lỗi chính tả thành bài toán phân loại, xác định một từ cùng với ngữ cảnh của nó làm đầu vào sẽ cho kết quả là nhãn có lỗi hay không. Các thuật toán học máy hiện đại sẽ có thể mô hình hoá để vừa sinh ra lỗi vừa sinh ra từ đúng.
Tiếp cận này khi sử dụng các mô hình học máy truyền thống như Support Vector Machine, Neural Network, … sẽ có nhiều hạn chế về độ chính xác và tốc độ xử lý. Vì vậy trước đây tiếp cận dựa trên thống kê và luật vẫn được ưu tiên hơn và ứng dụng trong thực tế nhiều hơn là tiếp cận học máy.
Gần đây, khi các mô hình học sâu ra đời, cùng với sự phát triển của phần cứng máy tính thì phương pháp học máy mới trở nên khả thi. Các phương pháp học sâu đã mô hình hoá ngữ cảnh tốt hơn và phần cứng mạnh hơn đã cho phép xây dựng các mô hình phức tạp, học trên dữ liệu lớn.
3.2. Hệ thống Deep Spelling
3.2.1. Mô hình đề xuất
Hệ thống Deep Spelling của chúng tôi phát triển dựa trên mô hình Transformer, là mô hình hiện đại, hiệu quả nhất hiện nay cho hầu hết các bài toán xử lý ngôn ngữ tự nhiên bằng học máy. Mô hình Transformer được phát triển và sử dụng cho rất nhiều hệ thống NLP (Xử lý ngôn ngữ tự nhiên) hiện tại như Dịch máy, nhận dạng giọng nói, Hỏi-đáp tự động, phân tích quan điểm, … của các công ty lớn như Google, Facebook, Baidu, …
Mô hình tổng quát của chúng tôi được thể hiện ở Hình 2.

H2. Mô hình tổng quát.
Các bước xây dựng mô hình Spelling cho Deep Spelling của chúng tôi:
Step 1: Xây dựng dữ liệu:
Chúng tôi thu thập số lượng văn bản tương đương khoảng 150 triệu câu, và sau đó sinh dữ liệu huấn luyện dựa trên các quy tắc và hiện tượng lỗi chính tả tiếng Việt.
Dữ liệu của chúng tôi được thu thập dựa trên các nguồn: trang tin tức online, wikipedia, văn bản pháp quy của nhà nước.
Step 2: Xây dựng và cải tiến mô hình:
Mô hình của chúng tôi dựa trên mô hình Transformer cho kiến trúc Encoder-Decoder. Chúng tôi thử nghiệm với các tham số khác nhau và bổ sung các cải tiến để mô hình cho kết quả tối ưu nhất.
Step 3: Thử nghiệm và tiếp tục điều chỉnh ở step 1 và step 2:
Chúng tôi thử nghiệm trên dữ liệu Test và sau đó điều chỉnh ở bước 1 và 2 để giải quyết các dự đoán sai tại bước thử nghiệm.
3.2.2. Kết quả thực nghiệm và so sánh
Để so sánh kết quả thực nghiệm chúng tôi sử dụng hai chỉ tiêu là dự đoán (detection) từ nào có lỗi, và sửa lỗi (correction) thay thế từ có lỗi. Với mỗi chỉ tiêu, chúng tôi sử dụng 3 độ đo là Precision, Recall và F-score.
Tập dữ liệu dùng để đánh giá là tập dữ liệu VSEC (VSEC2021/VSEC (github.com)), được lấy ngẫu nhiên từ 618 tài liệu có lỗi chính tả trên trang Tailieu.vn. Tập dữ liệu bao gồm 9341 câu, trong đó có 11202 lỗi chính tả thuộc 4582 loại lỗi chính tả khác nhau.
Bảng 1 trình bày kết quả thực nghiệm của chúng tôi khi so sánh với các nghiên cứu mới nhất về kiểm lỗi Chính tả Tiếng Việt, từ bài báo [https://arxiv.org/pdf/2111.00640.pdf]
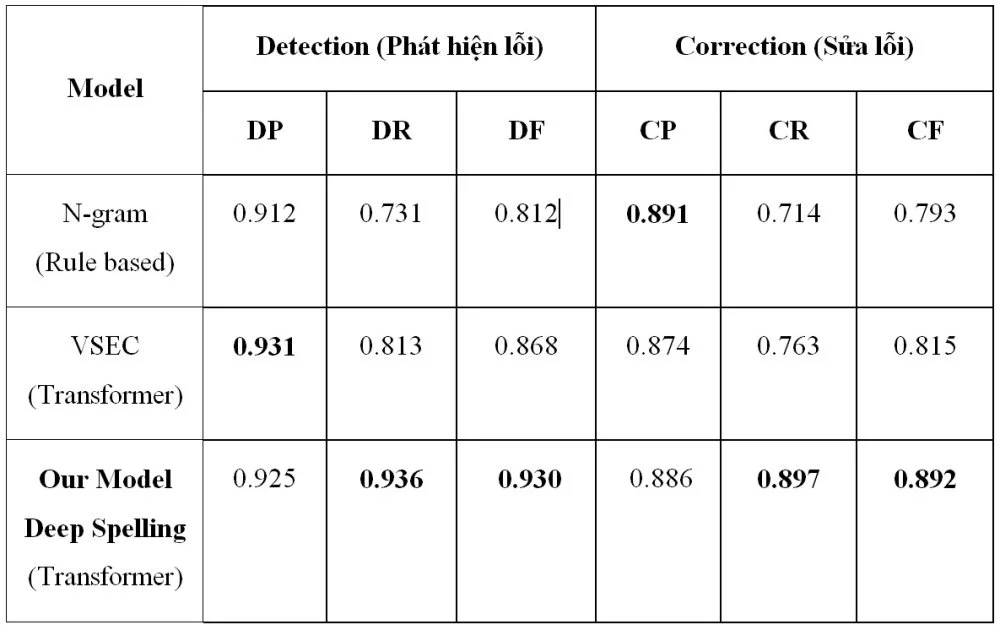
Bảng 1: So sánh kết quả của chúng tôi, hệ thống Deep Spelling với các nghiên cứu khác.
Chúng tôi so sánh kết quả của chúng tôi (Deep Spelling) với 2 mô hình của nghiên cứu trên bao gồm VSEC và N-gram. Hệ thống VSEC của họ cũng sử dụng mô hình dựa trên Transformer, còn mô hình N-gram là theo tiếp cận dựa trên thống kê và luật.
Nhận xét về kết quả của phương pháp của chúng tôi so với các nghiên cứu mới nhất về kiểm lỗi chính tả cho Tiếng Việt thông qua Bảng 1. Kết quả của chúng tôi vượt trội trên hầu hết các chỉ tiêu (trừ chỉ tiêu DP và CP là tương đương), với độ đo F-score (tức độ đo tổng hợp) hơn từ 6-7% cho cả chỉ số detection (phát hiện lỗi) và correction (sửa lỗi). Một chi tiết thú vị là chỉ số Recall của mô hình của chúng tôi vượt rất nhiều, hơn 12% ở nhiệm vụ detection và 13% ở nhiệm vụ correction. Điều này chứng tỏ hệ thống của chúng tôi có khả năng phát hiện ra nhiều lỗi hơn, sửa được nhiều lỗi hơn trong khi vẫn đảm bảo độ chính xác cao.
3.2.3. Các kết quả thử nghiệm trên thực tế
Chúng tôi khảo sát một số bản tin trên một số trang websites:
Báo VnExpress
Báo Vietnamnet
Zing News
Báo Bảo vệ pháp luật
Báo Phụ nữ Việt Nam
Báo Giao thông
Hà Nội Mới
Tin tức Quốc hội
Báo Chính phủ
Và thống kê được kết quả như sau:

Một số ví dụ thực tế:
Ví dụ, thông tin phụ huynh, học sinh tại nhiều tường (trường) trên cả nước; thông tin khách hàng của các ngân hàng lớn; thông tin đăng ký kinh doanh, nhân sự cơ quan nhà nước, bảo hiểm, hộ khẩu. (Nguồn: Hai phần ba dân số bị thu thập dữ liệu cá nhân trên mạng - VnExpress)
Quy định hiện hành cũng chưa có cơ chế cho phép cơ quan chuyên trách bảo đảm an ninh mạng phát huy tối đa khả năng tiếp cận, khai thác cơ sở dữ liệu như xác minh tài khoản ngân hàng, phong tòa (toả) tài khoản, tạm đình chỉ giao dịch, thu thập dữ liệu tài khoản viễn thông,... (Nguồn: Hai phần ba dân số bị thu thập dữ liệu cá nhân trên mạng - VnExpress)
"Các nước ý thức rất rõ vấn đề này nên khung phạt vi phạm rất cao, có khi lên đến hàng tỷ USD với doanh nghiệp kinh doanh thu thập dữ liệu cá nhân; mức phạt tù có khi lến (lên) đến 10 năm", Bộ trưởng nói. (Nguồn: Bộ trưởng Nguyễn Mạnh Hùng: Xây dựng chính sách bảo vệ dữ liệu cá nhân - VnExpress)
Năm 2020, Bộ đã rà quét, ngăn chặn 1.700 trang web có dấu hiệu lừa đảo, nếu không sẽ có 3,1 triệu người truy cập và xác xuất (suất) lừa đảo là rất lớn. (Nguồn: Bộ trưởng Nguyễn Mạnh Hùng: Xây dựng chính sách bảo vệ dữ liệu cá nhân - VnExpress)
Theo cựu thủ tướng Pakistan, xương của ông bị tổn thương, chân đang phải bó bột và sẽ mất khoảng 4-6 tuần mới có thể hoạt động bình hường (thường). (Nguồn: Cựu thủ tướng Pakistan nói bị trúng ba phát đạn - VnExpress)
Theo Phó thủ tướng, gần 5 năm sau khi Luật Quy hoạch ra đời nhưng quy hoạch tổng thể quốc gia chưa được phê duyệt, do "đây là vấn đề khó, chưa có tiền lệ, lần đầu tiền (tiên) trong lịch sử phê duyệt tổng thể quốc gia". (Nguồn: Bộ trưởng Xây dựng: Diện tích cây xanh đô thị không đạt mức tối thiểu - VnExpress Kinh doanh)
Theo lãnh đạo Thành ủy Hà Nội, việc luân chuyển, điều động cán bộ góp phần xây dựng đội ngũ cán bộ lãnh đạo quản lý đáp ứng yêu cầu phát triển của thủ đô trong giai (đoạn) 2021-2025 và những năm tiếp theo. (Nguồn: Sáu lãnh đạo sở ngành của Hà Nội được luân chuyển - VnExpress)
Từ năm 2011 trở đi, ông Trà ở (sở) hữu 7 ha keo tràm, khoảng 5 năm cho thu nhập một lần, mỗi vụ lời hàng trăm triệu đồng. Nguồn (Lão nông 'nghiện' khởi nghiệp - VnExpress)
Tuy nhiên, anh cho rằng có thể bản thân không có duyên với những việc học tập nhàm chán như bạn cùng trang lứa nên anh không bị hấp dẫn bởi những tiết học trên giảng đường, trái lại quỹ thời gian hầu như trải dài trong hàng giờ ở thư viện nghấu (ngấu) nghiến sách. (Nguồn: Chiến lược xây dựng doanh nghiệp hạnh phúc của cậu bé nghèo xứ Thanh (vnexpress.net))
Khoảng thời gian đó, Anat không thể mở cửa tủ và cũng không nhìn thấy bất cú (cứ) thứ gì. (Nguồn: Người đàn ông sống xót kỳ diệu sau 6h trên biển nhờ chiếc tủ lạnh cũ (saostar.vn))
IV. Chức năng của Hệ thống Deep Spelling
4.1. Các loại lỗi và sửa lỗi
Hệ thống của chúng tôi có khả năng kiểm tra phát hiện ra 6 loại lỗi sau:
4.1.1. Lỗi chính tả: Bao gồm các loại lỗi chính tả thông thường như liệt kê trong mục 1.2, ví dụ:

4.1.2. Lỗi thiếu từ: Hiện tượng thiếu từ được hệ thống phát hiện ra và gợi ý thêm từ. Lỗi này thường xảy ra do quá trình soạn thảo vội. Hệ thống sẽ phát hiện ra và gợi ý bổ sung từ thiếu.
4.1.3. Lỗi thừa từ: Hệ thống phát hiện một số hiện tượng thừa từ thuộc loại từ nhiễu bị thêm vào hoặc là từ bị lặp lại trong quá trình soạn thảo.
4.1.4. Lỗi viết hoa/thường: chủ yếu dành cho việc kiểm tra tên riêng viết hoa Nghị định số 30/2020/NĐ-CP của Chính phủ về công tác văn thư.
Ví dụ lỗi thiếu từ, thừa từ, viết hoa:

4.1.5. Lỗi dấu thanh:
Hiện đã có quy tắc đánh dấu thanh mới và đã tích hợp vào bộ gõ nên vấn đề này đã được giải quyết. Tuy nhiên một số văn bản cũ vẫn còn lỗi nếu xét theo quy định này, đồng thời một số nơi vẫn ưu tiên sử dụng đánh dấu thanh theo kiểu cũ. Vì vậy hệ thống cho phép Tuỳ chọn cả 2 loại này. Và cũng đồng thời cho phép người dùng chấp nhận cả 2 loại.

Ví dụ:

4.1.6. Lỗi khoảng trắng: Lỗi này thường xảy ra khi người dùng có thói quen dùng khoảng trắng để phân cách các dấu câu, dấu ngoặc đối với các từ trước nó.
Ví dụ:

Lưu ý: Các loại lỗi này được đưa vào Tùy chọn (Option), và vì vậy người dùng có thể lựa chọn sử dụng hoặc không sử dụng kiểm tra loại lỗi nào. Ví dụ có thể bỏ qua chức năng “lỗi khoảng trắng” và “lỗi đánh dấu thanh" vì nó không quan trọng.
Cũng lưu ý rằng, đối với các lỗi khó như lỗi thừa từ, lỗi thiếu từ có khả hệ thống sẽ nhận dạng nhầm với tỉ lệ cao hơn các lỗi khác. Với mục đích bắt thừa còn hơn bỏ sót thì người dùng có thể chọn option kiểm tra lỗi này, trong trường hợp bình thường thì có thể tuỳ chọn để bỏ qua không bắt loại lỗi này.
4.2. Các phương thức sử dụng Deep Spelling
Chúng tôi cung cấp 3 phương thức sử dụng thuận tiện cho người dùng:
4.2.1 Sử dụng trên Web do chúng tôi cung cấp dịch vụ.

Ngoài việc soạn thảo trực tiếp hoặc copy nội dung văn bản để kiểm tra chính tả, người dùng có thể upload file văn bản dạng Text, dạng MS Word, dạng Pdf (textual) hoặc là link của một trang Web.
4.2.2. Sử dụng Add-In tích hợp vào MS Word, gọi dịch vụ Spelling qua service của chúng tôi.
Người dùng có thể sử dụng Deep Spelling trực tiếp trong MS Word, tiện lợi trong quá trình vừa soạn thảo vừa kiểm tra chính tả.

4.2.3. Cài đặt hệ thống Deep Spelling trên server nội bộ (có thể trên từng máy nếu cấu hình máy đủ mạnh)
Chúng tôi cung cấp một lựa chọn cho phép tổ chức sử dụng có thể cài đặt hệ thống trên server nội bộ để hoàn toàn bảo mật về dữ liệu.
Đồng thời chúng tôi cũng có thể điều chỉnh mô hình, huấn luyện riêng cho dữ liệu đặc thù của tổ chức sử dụng để làm tăng độ chính xác của Spelling, và cũng có thể bổ sung các chức năng kiểm tra các lỗi khác theo nhu cầu. Ví dụ kiểm tra về tính chính xác của Chức danh và Tên người, tính chính xác giữa Tên đơn vị, tổ chức.
Hệ thống cũng có thể cung cấp chức năng Spelling theo dạng API để tích hợp vào các hệ thống sẵn có, ví dụ tích hợp vào hệ thống quản lý văn thư hiện đang dùng của đơn vị của bạn.
V. Cài đặt Hệ thống và Sử dụng
5.1. Hiệu suất của hệ thống
Chúng tôi đưa ra đây 3 cấu hình (gồm 1 cấu hình máy cá nhân và 2 cấu hình máy chủ) để tham khảo và hiệu suất của hệ thống khi chạy trên các cấu hình này:
Cấu hình máy cá nhân:
CPU: Intel Core i5 10500H 2.5GHz
RAM: 16GB
Storage: 256GB
OS: Linux
Tốc độ xử lý 100 trang A4 (tương đương 50000 từ): ~ 15s/trang
Cấu hình Server, ví dụ 1:
CPU: Intel® Xeon® Processor E5-2680 20M Cache, 2.70 GHz, 8.00 GT/s Intel® QPI
RAM: 16GB
Storage: 256GB
OS: Linux
Tốc độ xử lý 100 trang A4 (tương đương 50000 từ): ~ 6s/trang
Cấu hình Server, ví dụ 2:
CPU: Intel(R) Xeon(R) Gold 6252 CPU @ 2.10GHz
RAM: 64GB
Storage: 256GB
OS: Linux
Tốc độ xử lý 100 trang A4 (tương đương 50000 từ): ~ 3s/trang
5.2. Cài đặt
Các thư viện cần thiết cho chạy hệ thống:
Bản cài trực tiếp:
Python 3.8
NodeJS v14.20.1
Java 11
LibreOffice
Bản cài Docker:
Docker



